When visualizing issues from multiple projects it can be useful to group sprints with different naming schemes. With Dependency Map for Jira Cloud version 3.1.0 we introduce support for custom grouping of issues, which allows applying rules for renaming sprints to be able to visually group them into rows and columns in a Dependency Map. The same applies for other Jira issue fields as well.
Consider a case where we have a map with issues from two different project and that the project have slightly different naming conventions for the “Sprint” field:
- The first project: “Project Alpha Sprint 1 240501”, “Project Alpha Sprint 2 240601”, “Project Alpha Sprint 3 240701”
- The second project: “Increment 1”, “Increment 2” and so on.
By default, Dependency Map applies a “renaming rule” that renames the sprints by capturing the string “Sprint” and the number that follows directly after. This results in the following:
- The first project: “Sprint 1”, “Sprint 2”, “Sprint 3”
- The second project: “Increment 1”, “Increment 2”
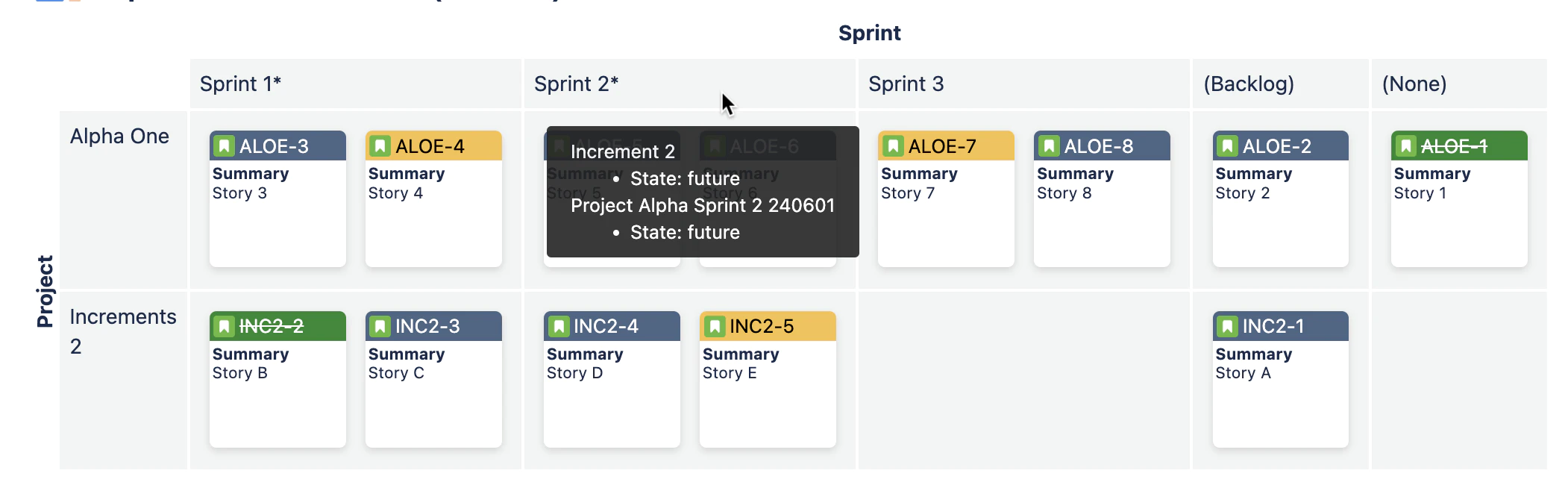
The map will then look like this:
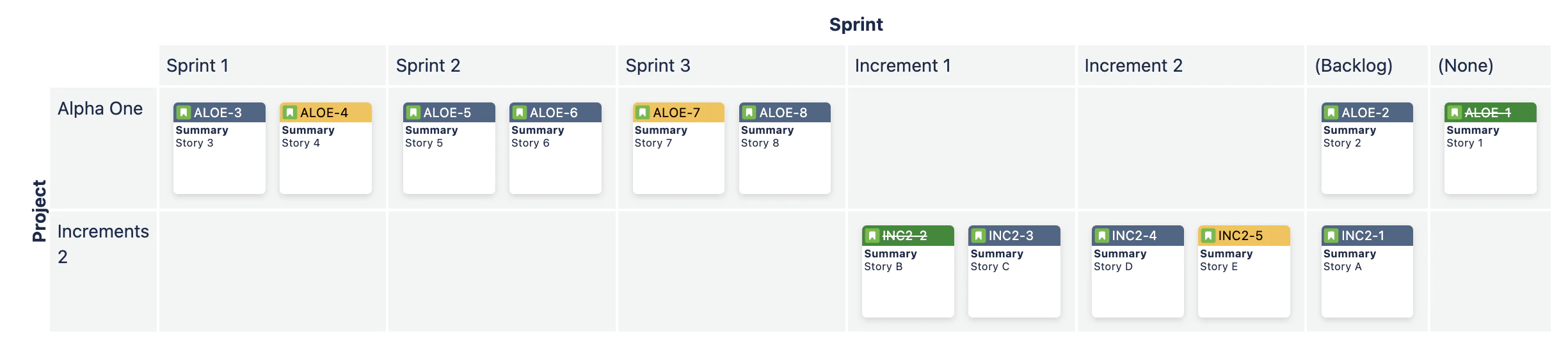
To be able to group the sprints from the two projects in columns, we still need to rename the sprints from the Increments project. To do this, we open the “Value grouping” section in the configuration pane and then we select the “Sprint*” entry in the Field dropdown where we find:
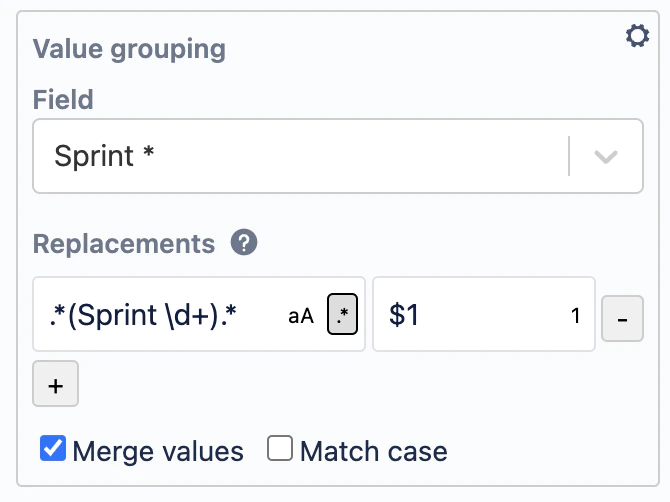
The default expression for Sprint is explained here: Manual for Dependency Map Cloud – Sprints
Next we add a second rule (click the “+” button) that replaces “Increment” with “Sprint”:
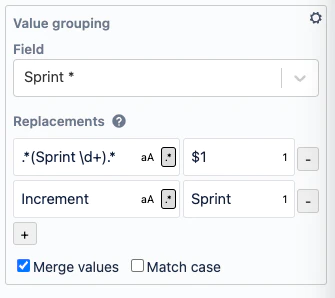
Now the map looks like this – note the hover for the “Sprint 2” column header, which displays the original sprint names:
For more information, see the documentation which describes this in detail:
Manual for Dependency Map Cloud – Grouping of issues